昨天QA跟我反馈说系统有几个接口反应很慢,起初我不以为意,因为这几个接口就是简单的写入和删除,最多就是再更新一下缓存,能有多慢。我让QA看看是不是网络抖动,延迟的问题,再看看我们的access_log里面响应时间是多少。QA说网络比较稳定,access_log里面显示要好几秒,这就让我有些诧异了。其中有一个删除用户XXX数据的接口响应特别慢,我们在测试环境去复现的时候果然复现了这个问题。当前端直接点击删除的时候,接口过了8秒多才返回,这肯定不正常了,而且access_log也印证了这一现象。
access_log如下所示:(后面的代码和日志我都以XXX来代替这次的业务场景)。
1 | 10.180.9.150 - 2017-06-20_15:58:55.960 DELETE /v1/xxx/user/comb/region-1497945389492-vfxil 200 95 (9586 ms) |
铁证如山,access_log显示了确实是我们接口响应慢了。这让我有些纳闷了,这个接口的业务场景非常简单,就是删除用户的一条XXX记录,并清除跟它相关的表信息,最后发出一个领域事件,由一个listener来清除缓存,代码如下。
1 | @Override |
关键是这个接口响应慢也不是每次都出现,响应慢的概率大概有50%,还是比较好复现的。还一个比较重要的信息就是,我们的SQL日志很快就打印完了,基本上我在POSTMAN一发出请求,我们的SQL也就执行完成了。但是POSTMAN此时并没有请求,那么就是说我们还没有返回response给前端。
怎么会这样?!不应该呀?难道是慢查询,索引的问题,我已经建了索引了呀,况且测试环境数据量这么小,不要索引也不至于这么慢啊!为了确定是不是慢查询的问题,我去咋们的APM工具(蜂巢的APM产品很强大,推荐大家使用)里面查询一下有没有捕获到慢查询的日志,结果很遗憾,并没有看到响应的慢查询日志。此时我就更困惑了。如果不是慢查询还能是什么。
走投无路的我只能祭出神器了——JProfiler,一款专业的APM工具。在折腾完一番环境配置部署等问题以后,我的客户端重要可以连上测试环境的jvm进行profiling了。用上了JProfiler感觉档次提高了好多,好像马上就能把问题解决了。下图是JProfiler的显示的调用过程。

调到这里,我只想说WTF!JProfiler显示这个HTTP调用只用了44ms就完成了。
我的内心又奔溃了,明明access_log显示花了8秒多,为啥JProfiler显示才44ms,难道JProfiler出错了?实际上,我更相信我自己的程序有问题,那为什么JProfiler显示我们的程序执行的很快呢?
看来JProfiler不能用了,我又想了很久。 
难道是因为我agent加的太多了,因为测试环境为了统计需要jvm参数里面加了jacoco的agent;还有,apm的agent。这么多agent会不会导致某种性能问题了,虽然我自己都不太相信,但本着大胆尝试地原则我果断去掉了两个agent再重试了几次,现象依旧!

幸好我内心强大,我还是很珍惜每次调试诡异BUG的机会的,因为能学到很多东西。此时的我已经没有什么手段了,事实摆着那里,接口响应很慢,也没有看到慢查询,JProfiler也没用了。然后我又祭出了我的第二个神器——BTrace。
相信很多人用过BTrace,这是在线调试的神器!虽然我不太想用这玩意,因为它要自己写脚本,内心有点排斥。但是我也没有别的办法了。准备再去看看BTrace的文档的时候发现BTrace的官方文档网站已经关了,WTF!
我突然想到了以前看到过的另外一款神器——Greys。Greys也是一款在线调试神器,是阿里开源的一个工具。以前我没有用过这个工具,这次形式所迫,不得以而学之。看完文档之后发现它非常强大,不比BTrace弱,而且对开发者比较友好,至少不用去写脚本。我用trace跟踪了一下那个deleteUserXXX方法,结果如下:
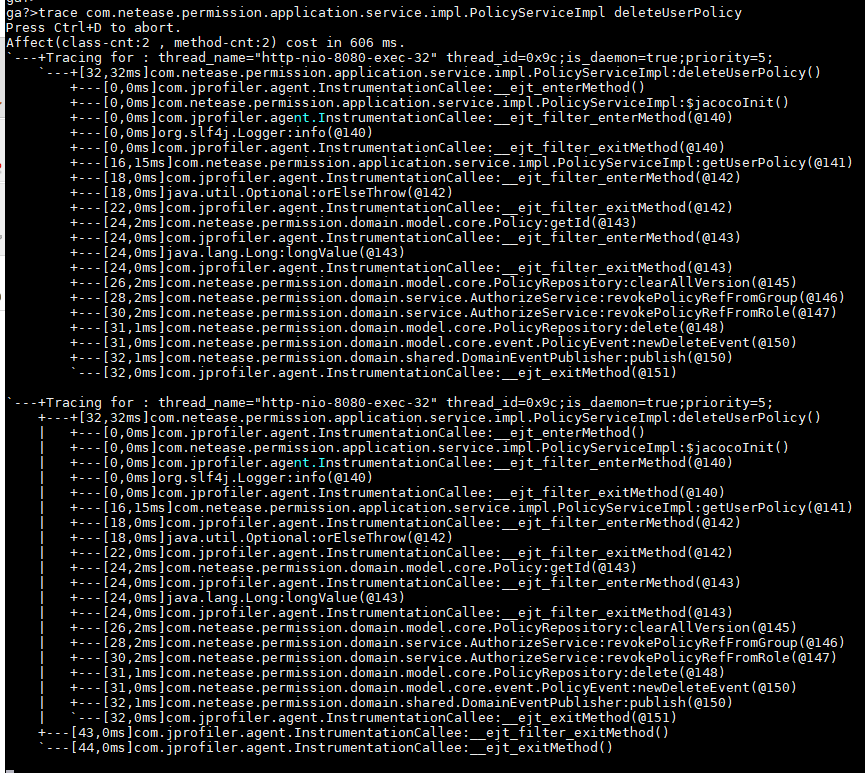
啥?为啥我发一次请求这个方法会被调用两次?而且还是被同一个线程执行两次?为此我专门在代码入口处加了一条无用的log来看看这个方法到底被执行了几次。log显示这个方法只执行了一次。那为什么trace显示执行了两次,我为此纠结了很久,有知道的小伙伴可以告诉我。
Greys没有提供太多有价值的线索给我,唯一有价值的信息就是那个线程名称。此时,我又灵关一闪,难道是Stop The World ? 因为我用的同步请求的方式,所以一个request只会被一个thread处理,而又没有满日志打印,说明不是数据库的问题,只能是jvm本身的问题,难道请求的时候触发了GC ? 又本着大胆尝试的精神我果断开启了jstat观察GC的情况。
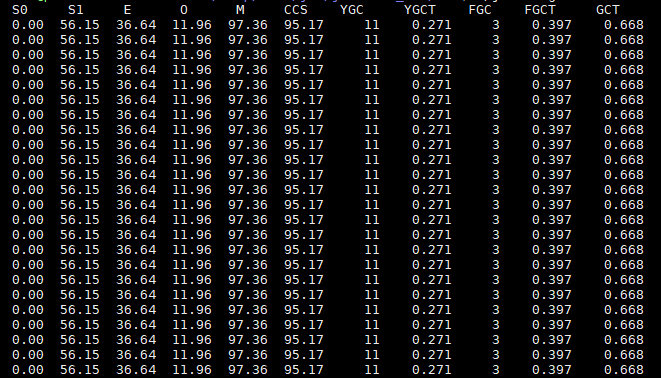
观察很久以后发现自己还是太年轻。别说FGC了,连YGC都没几次,根本不是GC的问题。这可如何是好?对了,还有一个工具没试过,jstack,反正这么多工具都用了,也不差这一个了。
在请求过程中我用jstack来查看线程的运行状态,得到了如下的运行堆栈。堆栈显示socket在读取什么东西
,到底是什么东西呢?
1 | "http-nio-8080-exec-2" #104 daemon prio=5 os_prio=0 tid=0x0000000006b1b000 nid=0x7392 runnable [0x00007f74dece9000] |
我拿着堆栈信息一通Google,最终发现下面这两个网页:
ReadAheadInputStream hangs on socket read
Server query cache vs protocol issue
啊哈,这个人的堆栈跟我们一样,这是MySQL的一个BUG。哈哈,我居然碰到了MySQL的一个BUG。似乎一个程序员在一个问题上调试了很久还没有找到原因时,总是急于把发现的蛛丝马迹套到某个相识的问题上,而且那个人跟我有着一样的运行堆栈!我现在多么希望就是这个原因啊!
在Bug #74979的说明中表示这个影响的版本是MySQL 5.7.4,但是我的MySQL 版本是5.7.14。为了确认是否是MySQL的问题,我专门找DBA来一起看这个现象。
起初,DBA也很诧异,SQL的执行速度是很快的,索引也没有问题,但是COMMIT很慢!这是为什么呢,我并不是MySQL专家,这么专业的事情还是主要交给DBA来分析。再和DBA复现了几次现象以后,DBA也有些纳闷了,再和其他的DBA沟通以后发现我的库所在的盘的IO很高,是磁盘IO的问题!WTF?!
DBA在给我的库换了一块盘以后一切恢复正常了,但是我此时的内心是这样的!

这个例子告诉我,有时候再多的分析也没有,不要想太多,想把基本的监控参数看清楚很重要!哈哈,当然,我再这个过程中又学到了很多新技能,就算这次坑爹的Debug过程花了我快1天半的时间,但我还是觉得很值得!

