原文链接:https://docs.microsoft.com/en-us/previous-versions/msp-n-p/dn568103(v%3dpandp.10)
通过使用不同的接口来分离读写操作,这种模式能最大化性能、可扩展性和安全性;能通过更高的灵活性来支持系统的演进;同时能在领域层面防止因更新命令引起的合并冲突。
背景与问题
在传统的数据管理系统中,命令(更新数据)与查询(请求数据)是在相同的一组实体集在单个数据仓库下执行的。这些实体可能是传统关系型数据库(比如:SQLServer)中一张或者多张表的多行数据的一个子集。
典型的,在这些系统中,所有的创建、读取、更新和删除(CRUD)操作在同一个实体上执行。比如,一个“客户”的DTO对象通过数据访问层(DAL)从数据仓库中检索出来并展示到界面上。用户更新了DTO对象中的几个熟悉,然后DTO对象通过DAL层被存回了数据仓库中。像图一所示,同一个DTO对象既被用于了读操作又被用于了写操作。

传统的CRUD模式在针对数据的业务逻辑十分有限的情况下能比较好的工作。一些开发工具提供的脚手架机制能迅速的创建数据层的访问代码,然后能按需调整。
然后,传统的CRUD方法有几个弊端:
- 这通常说明对数据的读和写操作存在不匹配,比如附加的列或者属性必须正确的更新即使它们不是操作的必须部分。
- 在一个协作的领域模型(例如多个Actor并行操作相同的数据集)中,当记录被锁定在数据仓库中,或者因为并发更新引起的更新冲突,此时会存在数据争取的风险。随着系统的复杂度和吞吐量增加,这些风险也逐渐加大。另外,因为数据存储和数据访问层的负载较重,加之检索必要信息的复杂性查询,传统方法同样对性能有着负作用。
- 因为一个实体同时暴露了读写操作,有可能一不小心在一个错误的上下文中暴露了数据,从而使得管理数据的安全性和权限更加繁琐。
解决之道
命令与查询责任分离是一种通过接口来区分开读数据(查询)与更新数据(命令)的模式。这表明用于查询的数据模型与用于更新的数据模型是不一样的。如图二所示,这些模型可以是独立的,虽然这不是必须的。
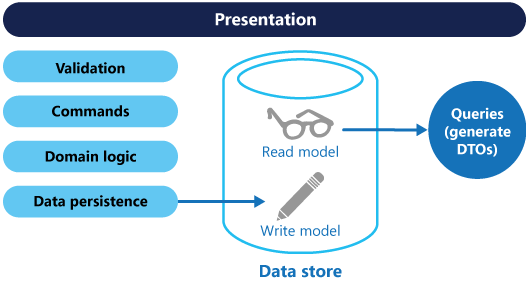
与基于CRUD系统中固有的单一数据模型相比,基于CQRS系统中分离的查询与更新数据模型能极大的简化设计与实现。然后,一个缺点是,不能像CRUD,CQRS代码不能通过脚手架的工具自动生成。
读数据的模型和写数据的模型可以访问相同的物理存储,可能通过使用SQL试图或者动态生成映射。然后,通常的做法是将数据分离到不同的物理存储,这样能最大化性能,可扩展性和安全性,如图三所示。
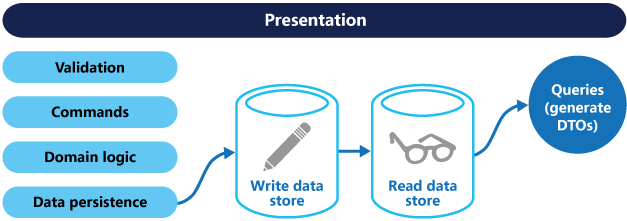
读存储可以是写存储的一个只读副本,也可以有完成不同的数据结构。使用多个只读副本可以提高查询性能和应用的UI响应性,尤其是在分布式的场景中,应用系统的实例可以与只读副本距离很近。某些数据库系统中,例如SQLServer,提供额外的副本故障转移功能来提高可用性。
分离读存储与写存储允许对方能独立的扩展来应对负载。例如,读存储一般都比写存储遇到的复杂要高得多。
当读模型包含非结构化的数据时,在读取应用系统中每个视图的数据或者从系统中进行查询时,性能将最大化。
问题与考虑
当实现这个模式时应当考虑一下几点:
- 将数据存储根据读写操作划分为独立的读存储和写存储,这能提高系统的性能和安全性,但在弹性和最终一致性方面,它增加了相当大的复杂度。读存储必须更新以反映写存储的变化,同时,很难检查用户何时基于一个老旧的读数据发出请求,这意味着操作不可能完成。
- 考虑将CQRS应用到你系统中最有价值部分,同时从经验中学习。
- 采用最终一致性的一个典型做法是使用事件溯源(EventSouring)与CQRS相结合,这样读模型就是一些列追加的命令执行的事件流。这些事件用于更新充当读模型的物理视图。
适用场景
该模式适用于以下场景:
- 协同的领域中针对同样的数据有多个操作并发执行。CQRS模型能在领域这个层次上提供最小化冲突的保证(任何出现的冲突都可以通过命令的方式来合并),即使是在更新同种类型的数据。
- 当时候基于任务视图的用户界面时(用户操作被引导为一些列复杂的步骤),同时你有一个复杂的领域模型,而且团队成员已经对DDD技术比较熟悉了。写模型拥有完整的完整的命令处理堆栈,包含业务逻辑、输入校验、业务校验,以确保写模型中每个聚合的所有内容是一致的。读模型没有验证逻辑或者验证堆栈,只需要视图模型需要的DTO对象。读模型与写模型是保持最终一致的。
- 在那些需要根据数据写入性能来微调数据读取性能的场景中,尤其是读写比非常高,需要水平扩容的时候。比如,在很多系统中,数据读取操作要比写入操作大几个数量级。为了适应该场景,考虑将读模型进行扩展,但是写模型只需要一个或者少数几个实例就可以了。少量的写模型能最小化冲突发生的概率。
- 一个团队可以专注于复杂的领域模型,而该模型是写模型的一部分;而另外一个相对缺乏经验的团队可以专注于读模型和用户界面。
- 系统期望能随着时间演进,同时能维持多个版本,或者业务逻辑会时常变化。
- 与其他系统进行集成,尤其是结合EventSouring,一个子系统临时的失败不应影响其他系统的可用性。
该模式不适用于以下场景:
- 领域模型或者业务逻辑很简单。
- 一个简单的CRUD风格的用户界面,以及其相关的数据访问操作就已足够。
- 实现跨越了整个系统。整个数据管理场景中特定组件使用CQRS可能很有用,但是需要考虑的是它经常会带来不必要的复杂性。
EventSouring与CQRS
CQRS经常与EventSouring相结合。基于CQRS的系统使用独立的读写模型,它们是为其相关的任务量身定制的,而且经常会分不到不同的物理存储上。当使用EventSouring时,存储的事件就是写模型,并且这是信息的权威来源。基于CQRS的读模型提供了数据的物化视图,典型的是作为高度非规范化的视图。这些视图是为用户界面和应用展示需要高度定制化的,这样能最大化展示和查询性能。
相比于使用某个时刻点的实际数据而言,使用事件流作为写存储,能避免在单一聚合上的更新冲突以及最大化性能和扩展性。事件可用于异步生成物化视图,而这些视图是由读存储填充形成的。
因为事件存储是信息的权威来源,所以当系统演进的过程中或者读模型必须改变的时候,是有可能删除物化视图并重放过去的所有事件来重建一个当前状态的新描述。物化视图实际上是数据的一个持久化只读缓存。
当结合CQRS和EventSouring时,需要考虑以下问题:
- 与任何读写存储分离的系统一样,基于该模式的系统也是最终一致的。生产事件和保存由这些事件发起的操作结果之间会存在一些延迟。
- 该模式引入了额外的复杂性,因为必须写代码来初始化、处理事件,并组装或者更新因为查询或者读模型所需要的合适的视图和对象。当与EventSouring相结合的时候,CQRS内在的复杂性使得一个成功的实现更加困难。这需要重新学习模型概念,以及一个不同的系统设计方法。然后,EventSouring使得建模更加简单,也更加容易重建视图或者创建一个新试图,因为数据变化的本质得以保留。
- 通过重放和处理特定实体或者实体集合的事件来生成用于读模型或者数据映射的物化视图可能需要充足的处理时间和资源消耗,尤其当需要对长时间段内值做求和或者分析操作时,因为可能需要检查每个所相关联的事件。这可以通过在预定的时间间隔内打数据快照来部分解决,例如记录下某些操作发生的总次数,或者实体的当前状态。
个人观点
CQRS是一种相当常见并且适用性相当广泛的架构模式,我曾经在多个真实的系统中见到该模式发挥巨大作用。该模式的核心观点在于将用于读和写的领域模型进行分割,根据实际的业务场景进行独立的开发和优化,这样带来的好处就是极高的扩展性和灵活性。我们再也不用纠结因为因为领域模型是一个而小心翼翼地处理并发、安全、性能等问题。但是任何架构都有两面性,就像文中所说的一样,该模式会引入额外的复杂性,如果你的业务场景比较简单,建议还是不要轻易尝试。至于EventSouring,个人持有保留意见,因为只保留事件记录的做法过于极端,即使通过快照优化,还是有点过于激进。我相信EventSouring会在少数几个关注于历史数据的业务场景中得到应用,例如审计、金融等,但这种业务相对比较特殊,适用性有限。

